문제 사항 1. 책 조회 페이징 API (TPS 4.3)
책 조회에 대한 페이징 API를 구현한 뒤, Ngrinder를 통해 TPS를 확인해보니 4.3 으로 매우 낮은 상태였습니다. 책 ID(클러스터 인덱스)로 조회했을 때 최대 TPS는 약 230에 비해 현저히 낮은 상태였습니다. 이 문제점을 개선하기 위해 다음과 같은 과정을 진행했습니다.
테스트 환경
NCLOUD 애플리케이션 서버 (2CPU / 2GB)
NCLOUD ngrinder 에이전트 및 컨트롤러 서버 (2CPU / 2GB)
MySQL 마스터 / 슬레이브 이중화로 구성 (Book 테이블에는 500만건의 더미데이터 생성)
개선 전 상태
API를 호출하면 쿼리문이 2번 나갑니다. 처음은 OFFSET 방식으로 쿼리가 나가고, 그다음은 총 개수를 얻기위해 카운트 쿼리가 나갑니다.

첫번째 쿼리문의 EXPLAIN을 확인하면 테이블 풀 스캔에 filesort 방식으로 옵티마이저가 행동합니다.

MySQL EXPLAIN 결과에서 일반적으로 데이터가 많은 경우, Using Filesort와 Using Temporary 방식은 좋지 않습니다.
Filesort는 MySQL에서 내부적으로 테이블을 Sort Buffer에 옮겨 정렬하는 작업을 거칩니다. 정렬이 완료된 후, 결합이 필요한 데이터가 있다면 합치는 작업을 거친 후 데이터를 내려줍니다. (물론 단일 테이블인 경우엔 그대로 내려줍니다)
개선 과정 1. 인덱스 생성
옵티마이저의 filesort 방식이 아닌 인덱스 테이블을 사용할 수 있도록, created_at 칼럼에 인덱스를 생성했습니다.
CREATE INDEX idx_created_at ON book (created_at DESC);

이제 인덱스를 타고 duration이 0.0004925초로 개선이 되었지만, OFFSET에서는 큰 단점이 존재합니다. OFFSET에서 300만 + 로 넘어가면 즉 페이지수가 넘어갈수록 점점 쿼리속도가 느려지고 다시 duration을 확인하면 2.6909초로 대폭 느려지며, 옵티마이저가 다시 filesort로 행동했습니다.
이유는 OFFSET은 10개의 데이터만 조회한다고 해도 앞 300만 건의 데이터도 모두 읽습니다 즉 300만 + 10개의 데이터를 순차적으로 읽어들이고 300만건의 데이터는 버리고 10건만 보냅니다. 또한 이 300만건은 created_at의 인덱스 테이블에서만 읽는게 아니라 다른 칼럼도 읽기 위해 다시 테이블로 가서 데이터를 읽기 때문에 시간이 상당히 증가합니다.
개선 과정 2. 커버링 인덱스 사용
이때 다른 칼럼까지 복합으로 인덱스를 생성하면 그래도 시간이 줄어들지 않을까 예상하고, 모든 필요한 칼럼들. 즉, select절과 orderby절에서 사용하는 모든 칼럼들을 포함하는 복합 인덱스를 생성했습니다.
CREATE INDEX idx_book_cover ON book (created_at DESC, book_id, book_code, book_name, page_count, updated_at);

커버링 인덱스 방식으로 인덱스 풀 스캔을 뜻합니다. 이제 더이상 테이블 행에 접근하지 않으므로 효율적으로 되었습니다. duration을 확인해보면 0.000325초 이고, OFFSET이 300만 + 되어도 duration이 0.5792초로 이전에 비해 상당히 개선되었습니다.
하지만 커버링 인덱스는 너무 많은 인덱스가 필요하고(앞으로 조건 절이 추가되면 더 추가될 가능성이 있습니다), 인덱스 크기가 커지며, insert나 update가 일어나면 인덱스 테이블도 수정하기 때문에 새로운 성능문제가 발생할 요인이 있습니다.
개선 과정 3. NO-OFFSET 방식으로 개선 (TPS 4.3 -> 245, MTT 4,612.8 -> 81.3)
애초에 OFFSET을 사용하지 않으면 개선될 수 있습니다. 다만, 페이지 번호로 페이지네이션 구현이 불가능하고, 무한 스크롤 (더보기) 방식으로 페이지네이션을 구현해야 하기 때문에 함부로 결정할 수 없습니다. 만약 가능하다면 이 방식도 꽤 좋을 것 같아 어쨋든 진행했습니다.
NO-OFFSET 방식으로 개선하기 위해, 조건절 칼럼은 인덱스 적용이 필수 입니다. (이전에 생성했던 인덱스는 다 지웠습니다.)
CREATE INDEX idx_created_at ON book (created_at DESC);
OFFSET 대신 이제 where 절로 조회합니다.
SELECT * FROM BOOK WHERE created_at <= '2022-05-31 21:43:43.712214' ORDER BY created_at desc LIMIT 10;

인덱스 풀 스캔 방식이 아닌 인덱스 레인지 스캔과 커버링 인덱스 방식으로 동작됩니다. duration은 0.00044925초로 상당히 개선되었으며, 다만 페이지처럼 건너뛰는 방식을 할 수 없다는 단점이 존재합니다.
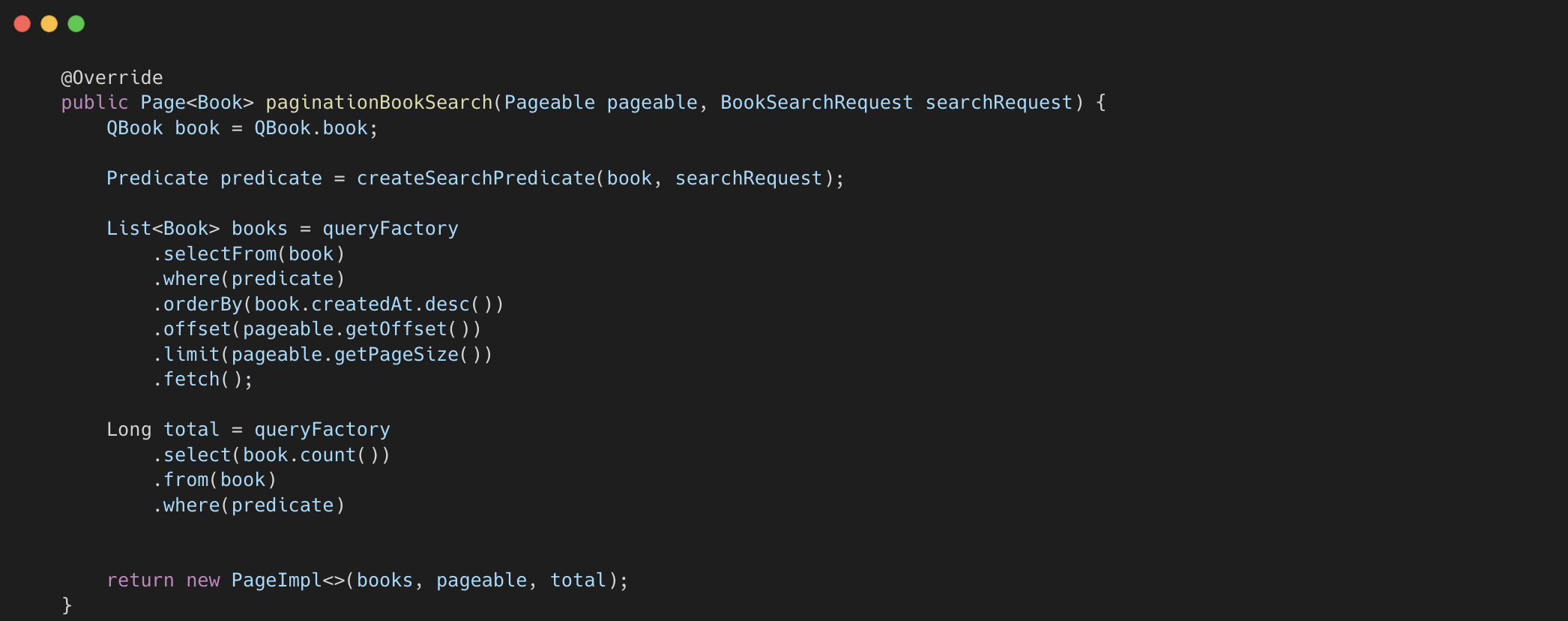
이를 스프링애플리케이션에서 구현하기 위해 동적으로 깔끔하게 쿼리를 짤 수 있는 QueryDSL를 사용했습니다.

클라이언트를 위해 다음 요청할 URL까지 만들어주면, API 응답값은 다음과 같이 작성됩니다.

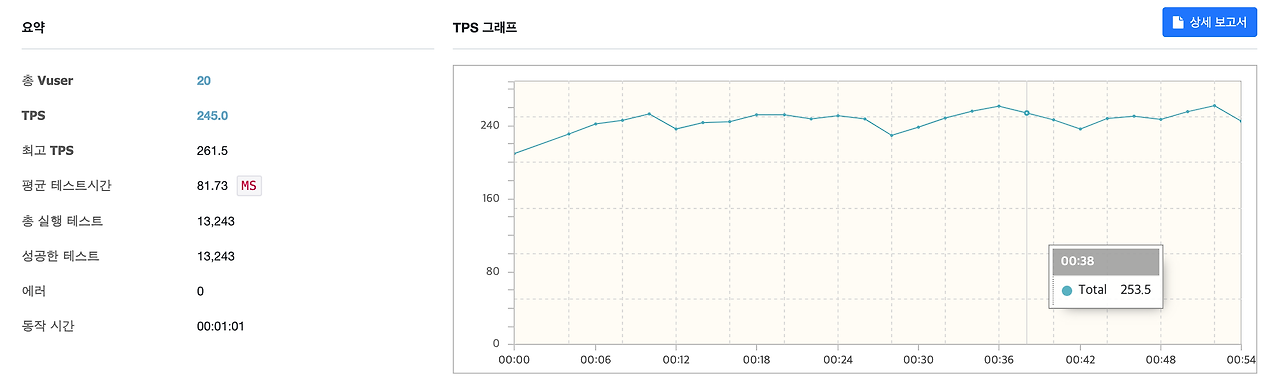
다시 성능 테스트를 진행하고 확인한 결과, VUser 20일때 TPS 245. MTT 81.3 으로 개선되었습니다.
문제 사항 2. 책 검색 페이징 API (TPS 5.4)
위의 개선은 사실 무한 스크롤 방식 일때 뿐 개선이지, 보통은 페이지로 구현됩니다. 그래서 OFFSET 방식으로도 개선을 할 필요성이 있습니다. 아까 OFFSET 방식에서는 쿼리가 두번 발생했습니다. 이번에는 카운트 쿼리도 개선할 필요성이 있어보입니다.
다음은 카운트 쿼리 입니다.

책 검색 API에서는 다양한 조건이 들어갑니다. 이렇게 조건절에 여러개의 조건이 들어가면 성능이 급격히 안좋아지는 현상이 발생했습니다.

테이블 풀 스캔에 duration은 5.364 초 입니다. where 절의 book_name , page_count에 이미 인덱스를 생성한 상태에도 불구하고, 테이블 풀 스캔으로 진행되었습니다. 당연히도 조건이 한개일때는 적용되지만, 두개가 같이 들어가니 인덱스 테이블을 더이상 타지 않습니다.
EXPLAIN ANALYZE로 좀 더 확실히 해석했습니다.
Table scan on b1_0: 전체 테이블을 스캔합니다
Filter: ((b1_0.book_name like '%2%') and (b1_0.page_count < 300)): 테이블 스캔 후 두 조건으로 필터링합니다.
Aggregate: count(b1_0.book_id): 마지막으로 필터링된 행의 수를 집계합니다.
문제점은 인덱스를 사용하지 않고, 전체 테이블을 스캔하고 있다는 점과 필터링이 데이터를 읽은 후에 이루어집니다.
이 상태로 성능 테스트를 진행하면, 아까 OFFSET이 초반 페이지에서는 빠름에도 불구하고, TPS가 5.4 대로 나왔습니다.

개선과정 1. 커버링 인덱스 사용
1. 주로 책 이름과 페이지 카운트만 검색한다고 가정했습니다. (isbn인 book_code는 거의 검색안한다고 가정)
2. 복합인덱스를 생성할 때, 자주 검색되는 조건을 앞 순위에 넣었습니다. 책 이름이 가장 많이 검색한다고 생각되어 앞 순위로 지정했습니다. (추후에 여기서 큰 문제 발생)
3. 실제로 커버링 인덱스를 태우는 부분은 select를 제외한 나머지만 우선으로 수행
CREATE INDEX idx_book_covering_search ON book (book_name, page_count);

커버링 인덱스 및 인덱스 풀 스캔으로 duration 1.05s로 아까 5.364s에 비해 많이 개선되었습니다. (카운트 쿼리는 로우 개수를 읽지 select절이 필요없기 때문에 where절의 칼럼만으로 커버링 인덱스가 가능합니다)
QueryDSL에서는 다음과 같이 구현했습니다.
개선과정 2. like 절로 인해 인덱스 순서 변경 ( TPS 5.4 -> 18.9, MTT 1900 -> 528)
쿼리를 다시 보면 조건절에서 LIKE '%2%'로 검색이 진행되는데, 앞에 %가 붙으면 성능이 크게 저하됩니다. 만약에 '2%' 와 같이 검색한다면 0.0008초로 상당히 개선됩니다.
하지만, 앞에 %가 붙는 걸 유지하면서 조금 더 개선할 수 있는 사항이 존재합니다.
page_count를 먼저 검색하여 결과를 줄이고, 그 결과에 대해 LIKE 절을 적용하면 성능이 크게 개선될 것으로 예상되었습니다.

순서를 바꾸고 검색한 결과 카운트쿼리가 1.05s -> 0.6978s로 조금 개선되었고, 페이징 쿼리는 0.03s 로 나왔고, TPS를 다시 측정했습니다.

이전에 비해 조금 개선되었습니다 (TPS 5.4 -> 8.8 , MTT 1900 -> 1142)
여기서 한 가지 놓친 부분이 있었습니다. page_count를 먼저 검색하도록 했지만, index 생성 당시 book_name, page_count 순으로 생성했기 때문에 인덱스 테이블은 이 부분이 최적화되지 않았습니다.
CREATE INDEX idx_book_covering_search ON book (page_count, book_name);
인덱스 순서를 변경한 후, 다시 실행 시간을 측정한 결과 0.36초로, 이전의 0.69초에 비해 크게 개선되었습니다.

또한 TPS를 다시 측정한 결과, 전보다 더 개선되었습니다 (TPS 8.8 -> 18.9 , MTT 1142 -> 528)
개선과정 3. 캐시 적용 X , 페이지 건수 고정하기 (TPS 18.9 -> 219, MTT 528 -> 45.2)
앞서 18.9 TPS로 개선되긴 했지만, 최대 240이상 줄 수있는것에 비해 현저히 낮았습니다. 그렇다고, 쿼리 duration이 낮은거 아니냐고 하면 OFFSET페이징 API에서 초반 페이지에서는 약 30ms , 카운트 쿼리에서도 약 30ms로 굉장히 낮은 편인데도 불구하고 TPS가 낮았습니다.
캐시를 적용하는 방식으로도 개선할 방법이 있지만, 검색 API에서는 검색 조건에 따라 시시각각 바뀌기 때문에 불가능합니다. 또한, 카운트 테이블을 생성하는 방식도 같은 이유로 불가능합니다.
애초에 카운트 쿼리가 문제일 것이라고 생각이 들었기 때문에 한 가지 가정을 했습니다. 대부분의 요청이 검색 버튼을 클릭하고, 페이지 버튼을 통한 조회 요청이 거의 없을 경우
이럴 경우 검색 버튼을 클릭한 경우에만 Page 수를 고정하고 (카운트 쿼리는 발생하지 않게 하고), 다음 페이지로 이동하기 위해 페이지 버튼을 클릭했을 때만 실제 페이지 count 쿼리를 발생시켜 정확한 페이지 수를 사용하게 하면 됩니다.
이는 코드를 다음과 같이 구현하면 됩니다.
1. 검색버튼 클릭 여부(useBtn) 가 true 일 때, 10개의 페이지 수가 노출되도록 fixedPageCount 반환
2. 페이지 버튼 클릭했을 때 (useBtn = false), 실제 카운트 쿼리 발생 시켜 결과를 반환 (기존처럼 진행)
3. 페이지 버튼을 클릭했을 때, 전체 페이지수를 초과한 번호로 요청이 온 경우에는 마지막 페이지 결과를 반환

FixedPageRequest

검색 버튼을 클릭했을 때 , 쿼리는 이제 한 번만 나가고, 검색 버튼만을 눌렀을 때의 TPS 결과,

카운트 쿼리가 없어지니 역시나 TPS 18.9 -> 219, MTT 528 -> 45.2 로 개선되었습니다. 검색버튼 누르는 일이 많을 때 상당한 성능 개선을 볼 수 있습니다.
하지만 UX상에서 동적으로 페이지 번호가 바뀌는 상황이 불가능하거나 검색버튼 보다 페이지 번호를 누르는 일이 많으면 이 방식 역시 좋은 방식은 아닙니다. 그때는 첫페이지만 카운트쿼리를 하고, 그 후엔 프론트 영역에서 카운트를 캐싱하고 보내주는 방식으로 해결할 수 있을 것 같습니다.
Reference
https://jojoldu.tistory.com/530
'toy > 북챌린지' 카테고리의 다른 글
| 클라우드 환경에 내 로컬 DB 연결하기 (2) | 2024.08.26 |
|---|