사전 지식
이슈란
이슈란 팀이 프로젝트를 진행하면서 관리해야 할 모든 종류의 작업, 버그, 개선사항, 요청 등을 포괄합니다.
1. 이슈 유형
- 스토리(Story): 사용자 요구사항이나 기능 개발을 의미합니다.
- 버그(Bug): 시스템 오류나 문제를 추적합니다.
- 태스크(Task): 구체적인 작업 단위를 나타냅니다.
- 에픽(Epic): 여러 스토리와 태스크를 포함하는 큰 단위의 작업입니다.
2. 설명 및 요약(Description & Summary)
- 작업의 목적, 세부 내용, 예상 결과 등을 기술합니다.
이슈번호(PROJECT-1 같은 형식)를 사용하는 이유
- 커뮤니케이션 효율성
짧고 명확한 참조: "PROJECT-123"처럼 간단히 이슈를 지칭할 수 있음
구두 커뮤니케이션: 회의나 대화에서 쉽게 언급 가능
"PROJECT-123 버그 수정했어요" vs "로그인 페이지에서 발생하는 validation 오류 수정했어요"
- 시스템적 이점
유니크한 식별자: UUID나 DB의 auto increment와 달리 사람이 읽기 쉬운 형태
프로젝트 구분: PROJECT-1, BACKEND-1 처럼 프로젝트별 구분이 즉각적으로 가능
정렬/필터링 용이성: 숫자 기반으로 순차적 정렬이 자연스러움
# 1. 문제 상황 (이슈 번호 생성 시 발생한 동시성 문제)
프로젝트의 이슈를 생성하는 과정에서 동시성 문제(Race Condition)가 발생했습니다. 여러 사용자가 동시에 이슈를 생성할 때, 같은 이슈 번호(예: PROJECT-1)가 중복 생성되는 현상이 발견되었습니다.
문제가 발생한 코드는 다음과 같습니다
int issueNumber = (int) (issueRepository.countByProjectKey(project.getKey()) + 1);
이슈 번호 생성 과정을 살펴보면
- DB에서 현재 프로젝트의 총 이슈 개수를 조회합니다.
- 조회한 값에 1을 더해 새로운 이슈 번호를 생성합니다.
- 생성된 번호로 이슈를 저장합니다.
이 과정이 하나의 원자적인 단위로 실행되지 않기 때문에, 여러 사용자가 동시에 이슈를 생성할 때 같은 이슈 번호가 만들어질 수 있습니다.
아래 다이어그램에서 더 자세히 볼 수 있습니다.

1-1. synchronized나 ReentrantLock으로 해결이 될까?
이슈 생성 요청은 에픽, 스토리 등 이슈 타입에 따라 각각 다른 트랜잭션으로 처리됩니다.
하지만 이슈 번호를 생성할 때는 모두 동일한 DB 자원(프로젝트별 이슈 개수)에 접근합니다.
자바의 synchronized나 ReentrantLock은 단일 JVM 내의 메모리 공유자원만을 동기화 보장 하기 때문에 다음과 같은 한계가 있습니다
- 다중 서버 환경: 서버가 여러 대인 경우(Scale-out) 다른 서버의 락을 인식할 수 없습니다.
- 성능 이슈: 모든 이슈 생성 요청 메소드(프로젝트나 이슈 타입이 달라도)에 락을 걸게 되면 순차적으로 처리해야 하므로 심각한 성능 저하가 발생합니다.
따라서 애플리케이션 레벨의 락이 아닌, 데이터베이스 레벨의 동시성 제어(낙관적 락 또는 비관적 락)를 사용하는 것이 적절합니다.
1-2. 이슈 번호 관리를 위한 테이블 분리의 필요성
현재 이슈 테이블 구조입니다.

이 구조에서는 다음과 같은 문제가 있습니다.
- 낙관적 락 적용 불가
- 이슈 번호 생성을 위해 전체 이슈를 count하고 새 이슈를 저장하는 과정이 별도 작업
- count 쿼리와 이슈 저장 사이에 버전 관리가 불가능
- 비관적 락의 한계
- 이슈 테이블 전체에 락을 걸어야 함
- 다른 이슈 생성이 모두 대기 상태가 되어 심각한 성능 저하 발생
- 이슈 삭제 시 이슈 번호 생성 문제
- 이슈 삭제 후, 이슈를 생성할 때 똑같은 개수로 같은 이슈번호로 생성 문제
따라서 이슈 번호 관리를 위한 별도의 테이블 분리가 필요합니다.

1-3. 낙관적 락과 AOP를 활용한 이슈 번호 동시성 문제 해결
이슈 번호 생성의 동시성 문제를 해결하기 위해 두 가지 전략을 결합했습니다.
1. 낙관적 락 적용

2. AOP를 활용한 재시도 로직 구현
@Transactional과 함께 @Retry 사용 시 프록시를 만들 때 트랜잭션이 먼저 적용되고 커밋되도록 구성해야 합니다.
스프링 AOP에서 프록시는 기본적으로 @Order 값이 작은 것이 더 바깥쪽 프록시가 됩니다. @Transactional의 기본 순서는 가장 마지막(Ordered.LOWEST_PRECEDENCE)입니다.

프록시 실행 순서
- @Retry (외부) → 재시도 로직 시작
- @Transactional (내부) → 트랜잭션 시작
- 실제 메서드 실행
- 트랜잭션 커밋
- 실패시 재시도
이렇게 구성해야 각 재시도마다 새로운 트랜잭션이 생성되어 정상적으로 동작합니다.
3. 실제 사용
트랜잭션 전파 속성을 REQUIRES_NEW로 설정한 이유는 호출하는 상위 메서드의 트랜잭션과 분리하기 위해서입니다. 만약 기본 전파 속성(REQUIRED)을 사용하면 상위 트랜잭션에 참여하게 되어, 재시도(Retry) 시에도 같은 트랜잭션 컨텍스트를 사용하게 되므로 낙관적 락 충돌이 해결되지 않습니다.

4. 테스트
테스트 방법은 ForkJoinPool의 스레드로 (프로젝트에 속한 팀원이 10명이라 가정) 이슈를 생성하도록 합니다.

10명의 사용자가 이슈를 생성하려다보니 테스트코드가 간헐적으로 실패합니다. 따라서 10명이 동시에 감당할 수 있는 Retry 횟수를 5회로 증가시켰습니다.

테스트 결과는 테스트를 하기 위한 준비 과정과 삭제 과정이 모두 포함되어 있기 때문에 정확한 테스트는 아닙니다. 비관적 락과 성능을 비교하기 위해서 입니다.
1-4. 비관적락을 활용한 이슈 번호 동시성 문제 해결
비관적 락은 데이터베이스 수준의 X-Lock(배타적 잠금)을 사용하여 동시성을 제어하는 방식입니다. 트랜잭션이 시작될 때 lock을 걸어 다른 트랜잭션이 해당 데이터에 접근하지 못하도록 막습니다.

데이터베이스에서의 동작

테스트 코드는 동일하게 유지됩니다. 비관적 락을 사용하면 동시 요청이 들어와도 순차적으로 처리되어 동시성 문제가 해결됩니다.

1-5. 이슈 번호 생성에 비관적 락 선택 이유
1. 트랜잭션 분리로 인한 안정성

이슈 번호 생성이 독립적인 트랜잭션으로 실행되고 다른 트랜잭션과 완전히 분리되어 데드락 발생 가능성이 없습니다.
또한 짧은 트랜잭션으로 락 유지 시간이 짧습니다.
2. 성능상 이점

비관적 락은 충돌 없이 한 번에 처리되고, 재시도가 필요가 없습니다. 앞에서도 낙관적 락은 800ms, 비관적락은 550ms 정도로 차이가 있습니다.
# 2. 문제 상황 (성능 테스트 결과 및 문제 상황)
2-1. 초기 성능 테스트 (VUser 10)
비관적 락으로 동시성 문제를 해결한 후, 실제 서비스에서의 성능을 확인하기 위해 nGrinder로 부하 테스트를 진행했습니다. 첫 테스트는 VUser 10명으로 진행했으며, 테스트의 정확성을 위해 이미지 업로드는 제외했습니다.
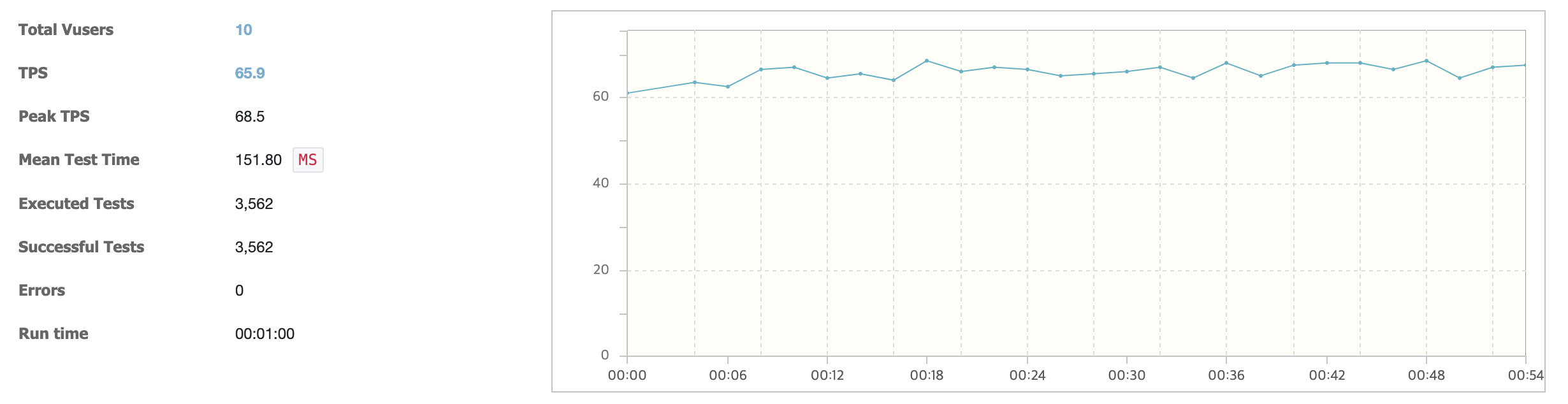
테스트 결과
- TPS(Transaction Per Second): 평균 65.9, 최대 68.5
- 평균 응답시간: 151ms
- 에러율: 0%
- 총 처리 건수: 3,562건
그래프에서 볼 수 있듯이 TPS가 안정적으로 유지되고 있으며, 응답시간도 매우 양호한 수준을 보여주었습니다.
2-2. VUser 20명의 동시 요청 시 Connection Pool 고갈
시스템의 한계를 확인하기 위해 VUser를 20명으로 증가시켜 테스트를 진행했습니다. 그 결과, DB Connection Pool 고갈 문제가 발생했습니다.

커넥션 풀이란
애플리케이션 서버가 띄워질 때 미리 서버와 DB가 연결된 커넥션을 미리 생성해 두고, 그 커넥션을 미리 만들어 둔 공간을 커넥션 풀이라 합니다.
조회를 할 때, 커넥션 풀에서 커넥션을 하나 빌려오고 DB 와 연결을 하고 DB 처리가 완료되면 커넥션을 반납합니다.
그 이 에러는 DB 처리를 위한 커넥션이 모자르다는 것이고, 커넥션 풀에 충분한 커넥션이 없거나, 빌려간 커넥션이 반납되지 않고 계속 사용중이거나 입니다.
실제 원인을 생각해보기 위해 다시 아까 수정한 코드를 반영해서 다이어그램을 그렸습니다.

커넥션 고갈의 문제점으로 파악되는 원인은
1. 낙관적 락 구현 시 적용했던 REQUIRES_NEW 옵션으로 인해 하나의 요청에서 2개의 Connection을 사용하게 됩니다. 현재는 비관적 락을 사용하고 있으므로 이 설정은 제거가 가능합니다.
2. 특히 이미지 업로드가 포함된 경우, S3 업로드 시간 동안 DB Connection이 불필요하게 유지됩니다.
3. 전체 이슈 생성 로직이 하나의 트랜잭션으로 묶여있어, Connection 유지 시간이 길어집니다. 이는 Connection Pool에서 사용 가능한 Connection 수를 제한하는 원인이 됩니다.
2-3. HikariCP 설정
기본 설정

1. max와 min을 동일하게 맞춰 항상 커넥션이 살아있도록 유지
이유
- 커넥션 생성은 비용이 큰 작업
- 갑자기 트래픽이 증가할 때 새로운 커넥션을 생성하는 시간 만큼 지연 발생
- 미리 커넥션을 생성해두면 즉시 응답 가능
- 특히 응답속도가 중요한 이슈 생성 시스템에서는 이 방식이 유리
2. connection-timeout을 3초로 유지
이유
- 시스템 상 안정성보다는 실시간 응답이 더 중요하다고 판단했습니다
- validation-timeout과 statement-timeout을 각각 1초,2초로 두고 총 connection-timeout을 3초로 두었습니다.
3. DB(MySQL)의 wait_timeout과 HikariCP의 max-lifetime의 관계
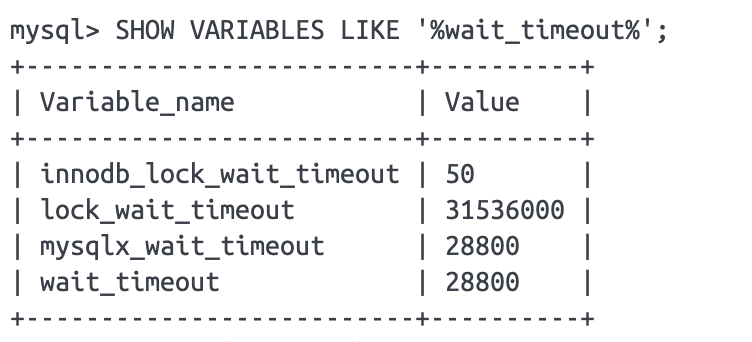
wait_timeout이란, DB가 유휴 상태의 커넥션을 강제로 끊기까지 기다리는 시간 입니다.
MySQL의 기본 값은 SHOW VARIABLES LIKE '%wait_timeout%'; 확인해보면 28800초 = 8시간 입니다.
문제는 max-lifetime을 DB의 wait_timeout보다 작게 설정해야 합니다. 만약 HikariCP의 max-lifetime이 DB의 wait_timeout보다 크다면, 다음과 같은 에러를 볼 수가 있습니다.
1. DB에서 커넥션 타임아웃 발생 (wait_timeout)
2. 애플리케이션은 이를 모른 채 커넥션 사용 시도
3. 'Connection is closed' 에러 발생
4. Connection Pool과 스레드의 상관관계 (HikariCP 데드락)
스레드와 함께 Pool Locking 이라는 유명한 이슈가 발생할 수 있습니다.
Pool Locking이란, 커넥션 풀의 모든 커넥션이 사용 중이고, 새로운 요청들이 계속 들어오고, 커넥션을 얻기 위해 많은 스레드가 대기할 때
스레드 병목 현상 발생하며, 최악의 경우 데드락이 발생할 수 있으므로 적절한 풀 개수를 설정해야 합니다.
예를들어 현재 한 트랜잭션 (하나의 스레드)에서 커넥션을 물고 있는 상태로, 커넥션을 하나 더 사용하려고 시도하는 데, 모든 스레드가 커넥션을 하나 씩 들고 풀에 남은 커넥션이 없어 서로가 서로를 기다리는 데드락이 발생하게 됩니다.
이 문제는 유명한 문제로 (https://github.com/brettwooldridge/HikariCP/wiki/About-Pool-Sizing) 공식이 존재합니다.
pool size = 최대 스레드 수 X (단일 스레드에서 최대 커넥션 수 - 1) + 1
하지만 공식이 여기에선 너무 극단적이므로 일반적으로 톰캣 스레드 수의 1/10 정도로 설정 (200/10 = 20) 했습니다.
hikari 설정

2-4. 트랜잭션 범위를 짧게 설정하기
기존 코드는 트랜잭션이 이슈생성 전체로 묶여있습니다.

실제 문제가 생길 수 있는 부분에만 트랜잭션을 둬서 짧게 가져가도록 다음과 같이 수정했습니다.

2-5. 문제 발생 원인과 성능 테스트 결과
기존에는 Hikari Pool의 설정을 하지 않았습니다. 즉, 커넥션 풀에 10개만 있는 상황이었고, VUser는 20인 상황에서 각 요청당 커넥션 2개 필요 (REQUIRES_NEW 때문) 했습니다.
이렇게 되면 5개의 요청만 정상 처리 가능 (10개 커넥션 ÷ 2)하고, 나머지는 커넥션을 기다리다 타임아웃이 생기며 심지어 첫 번째 커넥션을 잡고 두 번째를 기다리는 데드락 상황 발생한 것 이었습니다.
이 문제에 대한 다이어그램입니다.

앞서 Hikari Pool size를 늘리고, 트랜잭션 전파 옵션을 수정한 뒤 VUser 20으로 다시 테스트 했습니다.

VUser 10일 때와 달리 TPS도 절반으로 떨어지고, MTT도 증가했지만 커넥션 풀로 인한 에러는 더이상 발생하지 않았습니다.
# 3. 요약
주요 성과
1. 이슈 번호 생성 시 동시성 문제 해결
- 비관적 락을 활용하여 안정적인 이슈 번호 생성 구현
- 낙관적 락 대비 약 30% 향상된 성능 달성 (처리 시간 800ms → 550ms)
- 별도의 이슈 번호 관리 테이블 도입으로 구조적 개선
2. 커넥션 풀 관련 성능 문제 해결
- HikariCP 최적화 설정 적용 (pool size, timeout 등)
- 트랜잭션 범위 최소화 및 전파 속성 수정
- 불필요한 REQUIRES_NEW 제거로 커넥션 사용량 절반으로 감소
- VUser 20 환경에서도 안정적인 서비스 운영 가능
향후 개선 과제
1. 이미지 업로드 최적화
- 이미지 업로드 프로세스의 비동기 처리 구현
- S3 업로드 작업을 메인 트랜잭션에서 분리
- 이미지 업로드 실패 시의 롤백 전략 수립
2. 확장성 개선
- 분산 환경에서의 락 처리 전략 검토 (Redis, ZooKeeper 등 활용)
- 마이크로서비스 아키텍처 고려 시 이슈 번호 생성 전략 재검토
- 대규모 트래픽 대비 이슈 생성 프로세스 스케일링 방안 수립
3. 모니터링 강화
- 커넥션 풀 사용량 실시간 모니터링 체계 구축
'toy > AgileHub' 카테고리의 다른 글
| [이슈 #2] 멤버 초대 이메일 발송 설계 (2) | 2024.12.23 |
|---|---|
| [이슈 #1] 커넥션 풀 고갈 문제를 Redis Atomic 연산으로 개선하기 (3) | 2024.12.01 |
| Model has no value for 에러 발생 (1) | 2024.07.08 |
| 이슈 전체 조회 성능 개선하기 (0) | 2024.07.06 |
| 배포 하는데 걸리던 시간 13분을 5분으로 줄이기 (0) | 2024.05.14 |