https://babgeuleus.tistory.com/67
말만 들어도 어려워 보이는 트랜잭션에 대해 자세히 살펴보자 2편
https://babgeuleus.tistory.com/59 말만 들어도 어려워 보이는 트랜잭션에 대해 자세히 살펴보자 1편 개요 프로젝트를 진행하면서 가끔씩 service부분에서 @Transaction이 readOnly=true로 되어있어 현재 수행하는
babgeuleus.tistory.com
이전 시간에는 트랜잭션의 장애와 로그 회복기법에 대해 배웠습니다.
이번 시간에는 병행 제어에 대해 배우겠습니다.
문제의식
데이터베이스 관리 시스템은 여러 사용자가 데이터베이스를 동시에 공유할 수 있도록 여러 개의 트랜잭션이 동시에 수행되는 병행수행을 지원합니다. 병행수행은 실제로 여러 트랜잭션이 차례로 번갈아 수행되는 인터리빙 방식으로 진행됩니다.
그런데 병행 수행되는 트랜잭션들이 서로 다른 데이터를 사용하여 연산을 수행할 때는 괜찮지만 동시에 같은 데이터에 접근하여 변경 연산을 실행하려고 하면 원치 않은 결과가 나올 수 있습니다.(운영체제에서 배운 동시성 접근을 생각하시면 편합니다.) 그래서 이 문제를 해결하기 위해 병행제어 혹은 동시성제어를 이용합니다.
문제 상황 예시
데이터베이스에서 동시성 접근이 어떻게 일어나는지 확인해봅시다.
1. 갱신 분실
데이터베이스에 x=3000의 값이 들어있다고 해봅시다.
트랜잭션 T1은 x를 가져와 1000을 더하는 연산을 수행하는 역할을 합니다.
트랜잭션 T2는 x를 가져와 1000을 빼는 연산을 수행하는 역할을 합니다.
T1과 T2는 데이터베이스에 동시에 접근 가능한 병행수행을 할 수 있습니다.
이때 T1이 먼저 실행되어 데이터베이스에 있는 3000인 x를 read()합니다. 그리고 트랜잭션이 수행되다 x를 4000으로 바꾸고 commit 하기 직전에 트랜잭션 T2로 바뀌고 T2는 데이터베이스에 있는 x를 가져오는데 이 x에는 여전히 3000이 저장돼 있습니다. 그러고 나서 T2가 수행되어 x 2000을 커밋하여 데이터베이스에 2000 혹은 커밋을 했지만 아직 데이터베이스에 x가 3000일 때 혹은 반영되어 x가 2000이 됐습니다.
다시 T1이 수행되어 x 4000을 반영한다면 데이터베이스에서 x가 2000 됐다가 4000으로 저장됩니다.
우리가 원하는 결과는 3000-1000+1000인 3000일 텐데 4000으로 트랜잭션 T2 갱신이 분실되었습니다.
여기서 잠깐! 딴 길로 새겠습니다. 원치 않은 분들은 넘어가시길 바랍니다. 제가 위에 문제상황을 써가며 운영체제에서의 스레드가 텍스트 스위칭 할 때와 트랜잭션이 스위칭되는 상황이 비슷하여
이 스레드와 트랜잭션이 곧 스레드=트랜잭션인가 헷갈렸습니다.
다행히도 이에 대한 질문은 다음 글에서 상당 부분 해결이 되었습니다. ^^
https://zzang9ha.tistory.com/414
Spring Thread, Transaction, Connection 관계
📎 Spring Thread, Transaction, Connection 관계 안녕하세요, 최근 토비의 스프링 도서로 스터디 중 아래와 비슷한 질문이 있었습니다. "트랜잭션이 새로 생성될 때 스레드가 새로 생성될까요?" 이와 관련
zzang9ha.tistory.com
위 블로그를 요약하면 보통 하나의 스레드에서 여러 개의 트랜잭션을 관리합니다.
이 구절은 곧 스레드와 트랜잭션은 다른 개념이고 저 위의 상황은 두 개의 서로 다른 스레드가 데이터베이스에 동시 접근해서 트랜잭션을 수행하는데 데이터베이스는 인터리빙 방식으로 한 스레드의 트랜잭션을 실행하다가 콘텍스트스위칭하여 다른 스레드의 트랜잭션을 실행하는 상황일 것입니다.
(매우 주관적인 생각이며 틀린 부분이 있다면 지적해 주시면 정말 감사하겠습니다)
암튼 이런 갱신 분실을 막기 위해서 데이터베이스는 순차적으로 실행을 해야 될 것입니다. 즉 트랜잭션 T1이 완전히 수행될 때까지 트랜잭션 T2가 수행하지 못하도록 막고 T1이 완전히 커밋하여 데이터베이스에 반영되고 나서야 T2가 접근할 수 있도록 해야 합니다.
2. 모순성
또한 이런 상황도 막아야 합니다. 하나의 트랜잭션이 여러 개의 데이터 변경연산을 실행할 때
트랜잭션 T1이 데이터 X를 접근하여 처리하고 데이터 Y를 접근하여 처리를 합니다.
그런데 T1이 데이터 X를 접근하여 완전히 처리하고 갱신분실이 일어나지 않게 순차적으로 트랜잭션 T2가 실행되어 데이터 Y에 접근하여 Y의 값을 변경하고 반영한 다음 T1이 데이터 Y를 접근하면서 T2에 의해 변경된 값을 처리합니다.
이게 무슨 문제냐고 반문하겠지만 이는 트랜잭션 T1이 트랜잭션 T2로 인해 데이터 X와 데이터 Y를 서로 다른 상태의 데이터베이스에서 가져와 연산을 실행하기 때문에 결과를 신뢰할 수 없는 모순 상태입니다.
해당 문제를 해결하기 위해서는 트랜잭션 T1의 수행이 완료된 다음에 트랜잭션 T2를 수행하면 데이터베이스는 순차적으로 수행하며 모순성의 문제가 발생하지 않습니다.
3. 연쇄 복귀
또한 이러한 문제도 있습니다. 트랜잭션이 완료되기 전에 장애가 발생하여 rollback연산을 수행하면, 이 트랜잭션이 장애 발생 전에 변경한 데이터를 가져가 변경 연산을 실행한 또 다른 트랜잭션에도 rollback연산을 연쇄적으로 실행해야 합니다. 그런데 장애가 발생한 트랜잭션이 rollback연산을 실행하기 전에, 변경한 데이터를 가져가 사용하는 다른 트랜잭션이 수행을 완료해 버리면 rollback연산을 실행할 수 없어 큰 문제가 발생합니다.
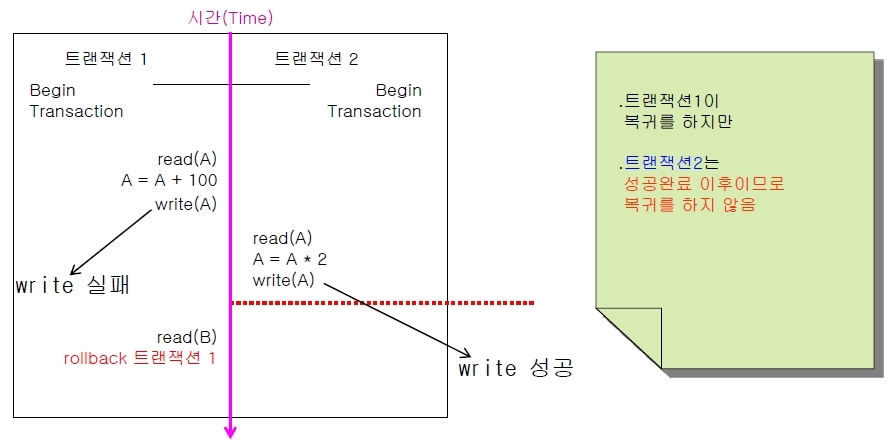
위의 사진처럼 트랜잭션 2가 완전히 실행되어 종료하면 rollback을 하여도 이미 종료된 트랜잭션이 복귀를 하지 않습니다.
이러한 문제를 해결하기 위해 역시나 순차성을 이용하면 해결을 할 수 있을 것입니다.
해결책
여러 트랜잭션을 병행 수행할 때는 (트랜잭션들이 차례로 번갈아 가면서 수행되는 인터리빙 방식) 트랜잭션들의 연산을 실행하는 순서가 중요합니다.
트랜잭션 스케줄
트랜잭션 스케줄은 트랜잭션에 포함되어 있는 연산들을 수행하는 순서입니다. 일반적으로 하나의 트랜잭션에는 많은 연산들이 포함되어 있어 여러 트랜잭션을 병행 수행하는 경우 트랜잭션들의 각 연산을 실행시키는 순서인 트랜잭션 스케줄도 여러 가지 있을 수 있습니다. 트랜잭션 스케줄은 세 가지 유형으로 구분할 수 있습니다.
1. 직렬 스케줄
직렬 스케줄은 인터리빙 방식을 이용하지 않고 트랜잭션 별로 연산들을 순차적으로 실행시키는 것입니다. 트랜잭션이 직렬 스케줄을 따라 수행되면 모든 트랜잭션이 완료될 때까지 다른 트랜잭션의 방해를 받지 않고 독립적으로 수행합니다.
즉, 트랜잭션 T1이 먼저 혹은 T2가 먼저 실행되지만 완전히 수행이 완료될때까지 다른 트랜잭션이 수행을 못합니다.
이것은 정확한 결과를 얻을 수 있지만 병행 수행이라고 할 수 없기 때문에 직렬스케줄은 잘 안 쓴다고 합니다.
2. 비직렬 스케줄
비직렬 스케줄은 인터리빙 방식을 이용하여 트랜잭션을 병행해서 수행시킵니다. 트랜잭션이 돌아가면서 연산들을 실행하기 때문에 하나의 트랜잭션이 완료되기 전에 다른 트랜잭션이 연산이 실행될 수 있습니다. 이렇게 되면 당연히 갱신분실, 모순성, 연쇄 복귀등의 문제가 발생할 수 있어 최종 수행 결과의 정확성을 보장할 수 없습니다.
트랜잭션들의 연산들을 실행하는 순서에 따라 다양한 비직렬 스케줄이 만들어질 수 있으며 이중에는 모순이 없는 정확한 결과를 생성하는 비직렬 스케줄도 있으므로 잘 선택하면 됩니다.
3. 직렬가능 스케줄
비직렬 스케줄 중에서 정확한 결과를 생성하는 비직렬 스케줄을 선택하는 것인데 다수의 트랜잭션을 대상으로 비직렬 스케줄을 찾아내는 것이 어려울 뿐만 아니라, 하나씩 수행해 보면서 직렬스케줄과 같은 결과가 나오는지 비교하는 것도 간단한 작업이 아닙니다.
따라서 데이터베이스 관리 시스템에서는 직렬 가능성을 보장하는 병행제어기법을 사용합니다.
병행 제어 기법
로킹 기법
로킹 기법은 병행 수행되는 트랜잭션들이 동일한 데이터에 동시에 접근하지 못하도록 lock과 unlock이라는 2개의 연산을 이용해 제어합니다. 한 트랜잭션이 먼저 접근한 데이터에 대한 연산을 모두 마칠 때까지 해당 데이터에 다른 트랜잭션이 접근하지 못하도록 상호 배제하여 직렬 가능성을 보장합니다.
무조건 모든 데이터에 대해 독점권을 가진 트랜잭션만이 읽고 쓰고 할 수 있다는 것은 너무나 가혹합니다. 무슨 말이면 read연산은 여러 트랜잭션이 동시에 병렬적으로 수행해도 문제가 없다는 뜻이죠 그래서 lock연산은 두 가지로 나뉘게 되었습니다.
lock연산
1. 공용 lock
트랜잭션이 데이터에 대해 공용 lock연산을 실행하면, 해당 데이터에 read연산을 실행할 수 있지만 write 연산은 실행할 수 없습니다. 그리고 데이터에 대한 사용권을 여러 트랜잭션이 함께 가질 수 있습니다.(같이 read 할 수가 있음)
2. 전용 lock
트랜잭션이 데이터에 대해 전용 lock연산을 실행하면 해당 데이터에 read 연산과 write연산을 모두 실행할 수 있습니다. 그러나 전용 lock연산을 실행한 트랜잭션만 해당 데이터에 대한 독점권을 가질 수 있습니다.
하지만 이 기본로킹규약으로는 모순성이 발생할 수 있습니다.
트랜잭션 T1
lock(x);
read(x);
x=x+1000;
write(x);
unlock(x);
lock(y);
read(y);
y=y+1000;
write(y);
unlock(y);트랜잭션 T2
lock(x);
read(x);
x=x*0.5;
write(x);
unlock(x);
lock(y);
read(y);
y=y*0.5;
write(y);
unlock(y);트랜잭션 T1이 5번째까지 실행되고 x를 너무 빨리 풀어 T2트랜잭션으로 교체될 때 한 번에 끝까지 실행되어 y의 값이 변하게 됩니다. 그러고 T1나머지 y를 접근하여 결과를 내면 모순성이 발생하게 됩니다.
이런 문제를 해결하기 위해
2단계 로킹 규약을 추가하였습니다.
2단계 로킹 규약
모든 트랜잭션이 lock과 unlock 연산을 2단계로 나누어 실행해야합니다.
1단계. 확장단계: 트랜잭션이 lock연산만 실행할 수 있고, unlock 연산은 실행할 수 없는 단계 입니다.
2단계. 축소단계: 트랜잭션이 unlock 연산만 실행할 수 있고, lock연산은 실행할 수 없는 단계 입니다.
이러한 2단계 로킹 규약을 준수하는 트랜잭션은 첫 번째 unlock 연산을 실행하기 전에 필요한 모든 lock연산을 실행해야 합니다.
lock(x);
read(x);
x=x+1000;
write(x);
lock(y);
unlock(x);
read(y);
y=y+1000;
write(y);
unlock(y);트랜잭션 T1이 보시는 바와 같이 unlock하기전에 모든 데이터 접근에 lock을 해야합니다.
이렇게 2단계 로킹 규약을 적용하면 트랜잭션 스케줄의 직렬 가능성을 보장할 수 있습니다.
'공부방 > 데이터베이스' 카테고리의 다른 글
| 요구사항 보고 ERD작성 및 논리적 스키마 도출 방법 (0) | 2023.06.05 |
|---|---|
| 말만 들어도 어려워 보이는 트랜잭션에 대해 자세히 살펴보자 2편 (0) | 2023.05.30 |
| 말만 들어도 어려워 보이는 트랜잭션에 대해 자세히 살펴보자 1편 (0) | 2023.05.22 |